Kubernetes日志介绍
1. 容器日志
Docker的日志分为两类,一类是Docker引擎日志;另一类是容器日志。引擎日志一般都交给了系统日志,不同的操作系统会放在不同的位置。本文主要介绍容器日志,容器日志可以理解是运行在容器内部的应用输出的日志,默认情况下,docker logs显示当前运行的容器的日志信息,内容包含 STOUT(标准输出)和STDERR(标准错误输出)。日志都会以json-file的格式存储于 /var/lib/docker/containers/<容器id>/<容器id>-json.log,不过这种方式并不适合放到生产环境中。
- . 默认方式下容器日志并不会限制日志文件的大小,容器会一直写日志,导致磁盘爆满,影响系统应用。(docker log-driver支持log文件的rotate)
Docker Daemon收集容器的标准输出,当日志量过大时会导致Docker Daemon成为日志收集的瓶颈,日志的收集速度受限。- 日志文件量过大时,利用docker logs -f查看时会直接将Docker Daemon阻塞住,造成docker ps等命令也不响应。
Docker提供了logging drivers配置,用户可以根据自己的需求去配置不同的log-driver,但是上述配置的日志收集也是通过Docker Daemon收集,收集日志的速度依然是瓶颈。
log-driver 日志收集速度
- syslog 14.9 MB/s
- json-file 37.9 MB/s
能不能找到不通过Docker Daemon收集日志直接将日志内容重定向到文件并自动rotate的工具呢?答案是肯定的采用S6[2]基底镜像。
S6-log将CMD的标准输出重定向到/.../default/current,而不是发送到 Docker Daemon,这样就避免了Docker Daemon收集日志的性能瓶颈
2. Kubernetes 日志
Kubernetes日志收集方案分成三个级别
2.1 应用(Pod)级别
Pod级别的日志,默认是输出到标准输出和标志输入,实际上跟Docker容器的一致。使用kubectl logs pod-name -n namespace查看,具体参考:https://kubernetes.io/docs/reference/generated/kubectl/kubectl-commands#logs。
2.2 节点级别
Node级别的日志 , 通过配置容器的log-driver来进行管理,这种需要配合logrotare来进行,日志超过最大限制,自动进行rotate操作。
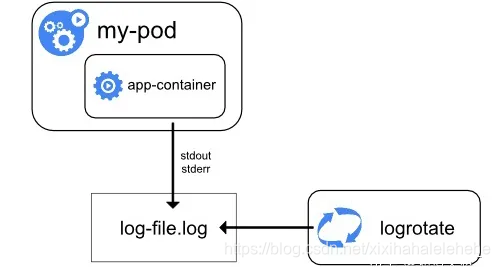
默认情况下,如果容器重启,kubelet 会保留被终止的容器日志。 如果 Pod 在工作节点被驱逐,该 Pod 中所有的容器也会被驱逐,包括容器日志。
节点级日志记录中,需要重点考虑实现日志的轮转,以此来保证日志不会消耗节点上全部可用空间。 Kubernetes 并不负责轮转日志,而是通过部署工具建立一个解决问题的方案。 例如,在用 kube-up.sh 部署的 Kubernetes 集群中,存在一个 logrotate,每小时运行一次。 你也可以设置容器运行时来自动地轮转应用日志。
例如,你可以找到关于 kube-up.sh 为 GCP 环境的 COS 镜像设置日志的详细信息, 脚本为 configure-helper 脚本。
当使用某 CRI 容器运行时 时,kubelet 要负责对日志进行轮换,并 管理日志目录的结构。kubelet 将此信息发送给 CRI 容器运行时,后者 将容器日志写入到指定的位置。kubelet 标志 container-log-max-size 和 container-log-max-files 可以用来配置每个日志文件的最大长度 和每个容器可以生成的日志文件个数上限。
当运行 kubectl logs 时, 节点上的 kubelet 处理该请求并直接读取日志文件,同时在响应中返回日志文件内容。
2.3 集群级别
集群级别的日志收集,有三种。
- 使用在每个节点上运行的节点级日志记录代理。
- 在应用程序的 Pod 中,包含专门记录日志的边车(Sidecar)容器。
- 将日志直接从应用程序中推送到日志记录后端。
2.3.1 节点代理方式
节点代理方式,在Node级别进行日志收集。一般使用DaemonSet部署在每个Node中。这种方式优点是耗费资源少,因为只需部署在节点,且对应用无侵入。缺点是只适合容器内应用日志必须都是标准输出。
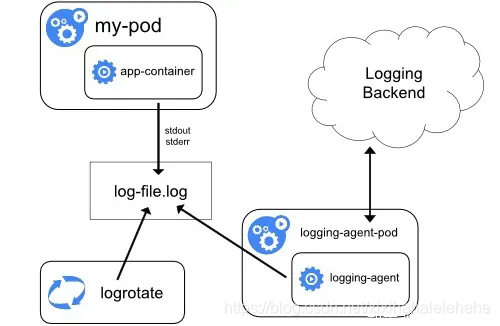
logging agent一般都会以 DaemonSet 的方式运行在节点上,然后将宿主机上的容器日志目录挂载进去,最后由 logging-agent 把日志转发出去。举个例子,我们可以通过 Fluentd 项目作为宿主机上的 logging-agent,然后把日志转发到远端的 ElasticSearch 里保存起来供将来进行检索。
- 优点:在于一个节点只需要部署一个 agent,并且不会对应用和 Pod 有任何侵入性。所以,这个方案,在社区里是最常用的一种。
- 缺点:这种方案的不足之处就在于,它要求应用输出的日志,都必须是直接输出到容器的 stdout 和 stderr 里。
2.3.2 使用 sidecar 容器运行日志代理
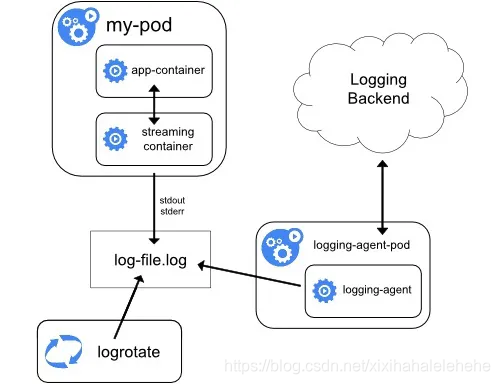
也就是在Pod中跟随应用容器起一个日志处理容器,有两种形式:
一种是直接将应用容器的日志收集并输出到标准输出(叫做Streaming sidecar container),但需要注意的是,这时候,宿主机上实际上会存在两份相同的日志文件:一份是应用自己写入的;另一份则是sidecar的stdout和stderr对应的JSON文件。这对磁盘是很大的浪费,所以说,除非万不得已或者应用容器完全不可能被修改。
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
在这种情况下,你用 kubectl logs 命令是看不到应用的任何日志的。而且我们前面讲解的、最常用的方案一,也是没办法使用的。那么这个时候,我们就可以为这个 Pod 添加两个 sidecar 容器,分别将上述两个日志文件里的内容重新以 stdout 和 stderr 的方式输出出来,这个 YAML 文件的写法如下所示:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-1
image: busybox
args: [/bin/sh, -c, 'tail -n+1 -f /var/log/1.log']
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-2
image: busybox
args: [/bin/sh, -c, 'tail -n+1 -f /var/log/2.log']
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
这时候,你就可以通过 kubectl logs 命令查看这两个 sidecar 容器的日志,间接看到应用的日志内容了,如下所示:
kubectl logs counter count-log-1
输出为:
0: Mon Jan 1 00:00:00 UTC 2001
1: Mon Jan 1 00:00:01 UTC 2001
2: Mon Jan 1 00:00:02 UTC 2001
kubectl logs counter count-log-2
输出为:
Mon Jan 1 00:00:00 UTC 2001 INFO 0
Mon Jan 1 00:00:01 UTC 2001 INFO 1
Mon Jan 1 00:00:02 UTC 2001 INFO 2
由于 sidecar 跟主容器之间是共享 Volume 的,所以这里的 sidecar 方案的额外性能损耗并不高,也就是多占用一点 CPU 和内存罢了。
但需要注意的是,这时候,宿主机上实际上会存在两份相同的日志文件:一份是应用自己写入的;另一份则是 sidecar 的 stdout 和 stderr 对应的 JSON 文件。这对磁盘是很大的浪费。所以说,除非万不得已或者应用容器完全不可能被修改,否则我还是建议你直接使用方案一,或者直接使用下面的第三种方案。
2.3.3 具有日志代理功能的边车容器
就是通过一个 sidecar 容器,直接把应用的日志文件发送到远程存储里面去。也就是相当于把方案一里的 logging agent,放在了应用 Pod 里。这种方案的架构如下所示:
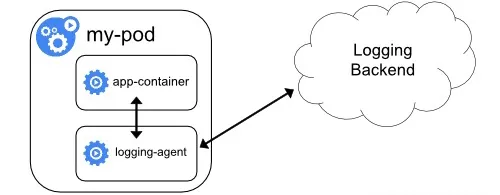
在这种方案里,你的应用还可以直接把日志输出到固定的文件里而不是 stdout,你的 logging-agent 还可以使用 fluentd,后端存储还可以是 ElasticSearch。只不过, fluentd 的输入源,变成了应用的日志文件。一般来说,我们会把 fluentd 的输入源配置保存在一个 ConfigMap 里,如下所示:
第一个文件包含用来配置 fluentd 的 ConfigMap。
要进一步了解如何配置 fluentd,请参考 fluentd 官方文档。
apiVersion: v1
kind: ConfigMap
metadata:
name: fluentd-config
data:
fluentd.conf: |
<source>
type tail
format none
path /var/log/1.log
pos_file /var/log/1.log.pos
tag count.format1
</source>
<source>
type tail
format none
path /var/log/2.log
pos_file /var/log/2.log.pos
tag count.format2
</source>
<match **>
type google_cloud
</match>
后,我们在应用 Pod 的定义里,就可以声明一个 Fluentd 容器作为 sidecar,专门负责将应用生成的 1.log 和 2.log 转发到 ElasticSearch 当中。。
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-agent
image: k8s.gcr.io/fluentd-gcp:1.30
env:
- name: FLUENTD_ARGS
value: -c /etc/fluentd-config/fluentd.conf
volumeMounts:
- name: varlog
mountPath: /var/log
- name: config-volume
mountPath: /etc/fluentd-config
volumes:
- name: varlog
emptyDir: {}
- name: config-volume
configMap:
name: fluentd-config
可以看到,这个 Fluentd 容器使用的输入源,就是通过引用我们前面编写的 ConfigMap 来指定的。这里我用到了 Projected Volume 来把 ConfigMap 挂载到 Pod 里。
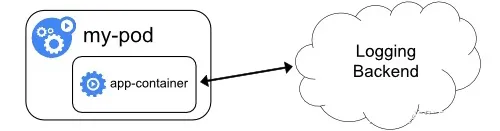
需要注意的是,这种方案虽然部署简单,并且对宿主机非常友好,但是这个 sidecar 容器很可能会消耗较多的资源,甚至拖垮应用容器。并且,由于日志还是没有输出到 stdout 上,所以你通过 kubectl logs 是看不到任何日志输出的。
3. 日志位置
有两种类型:在容器中运行的和不在容器中运行的。例如:
- 在容器中运行的 kube-scheduler 和 kube-proxy。
- 不在容器中运行的 kubelet 和容器运行时。
在使用 systemd 机制的服务器上,kubelet 和容器容器运行时将日志写入到 journald 中。 如果没有 systemd,它们将日志写入到 /var/log 目录下的 .log 文件中。 容器中的系统组件通常将日志写到 /var/log 目录,绕过了默认的日志机制。 他们使用 klog 日志库。 你可以在日志开发文档 找到这些组件的日志告警级别约定。
和容器日志类似,/var/log 目录中的系统组件日志也应该被轮转。 通过脚本 kube-up.sh 启动的 Kubernetes 集群中,日志被工具 logrotate 执行每日轮转,或者日志大小超过 100MB 时触发轮转。
参考: